当你在纠结选哪个模型时,人家已经用这套方法让 AI 自主开发了 100 万行代码
2026 年初,OpenAI 内部完成了一个疯狂的项目:
100 万 + 行代码,全部由 AI 生成
3 个工程师,5 个月时间
0 行人工编写的代码(注意,是故意的)
平均每个工程师每天产出 3.5 个 PR
产品现在每天有内部用户,还在持续迭代

最离谱的是什么?这个项目不是 demo,不是玩具,是正儿八经在生产环境跑的系统。
而工程师的工作不再是写代码,而是设计一个让 AI 能可靠写代码的系统。
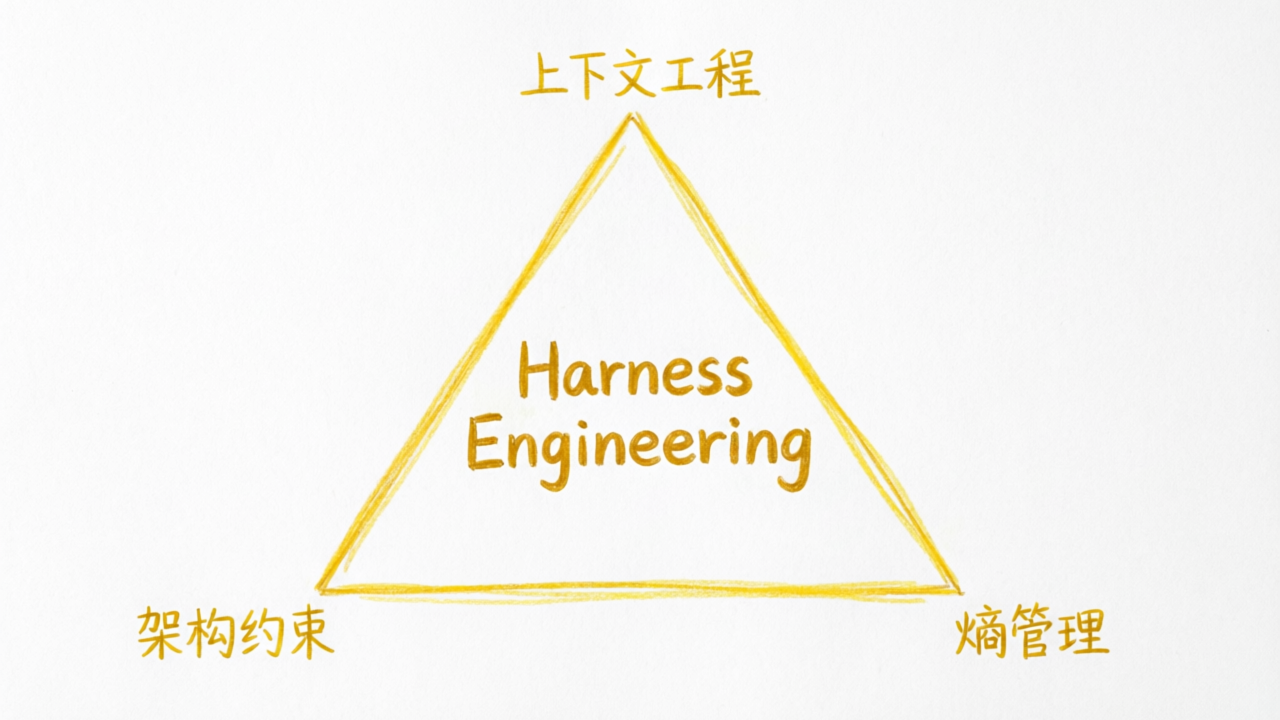
这个系统,就是今天要讲的 Harness Engineering(驾驭工程)。
想象一下你有一匹千里马(AI 模型):
它跑得快、力量大、天赋异禀
但它不知道要去哪儿,也不知道怎么拉车
Harness(马具) 就是缰绳、马鞍、车辕这一整套装备:
把马的力量引导到正确的方向
让它能拉车、能耕田、能送货
没有马具,马再厉害也只能在草原上瞎跑

Harness Engineering 就是设计和制造这套马具的学问。
Harness Engineering 是设计和实现以下系统的学科:
约束系统:规定 AI 能做什么,不能做什么
信息系统:确保 AI 知道该知道的一切
验证系统:检查 AI 做得对不对
修正系统:当 AI 犯错时能自动纠正
用 Martin Fowler 的话说:"这是在 AI 时代保持代码质量的新型工程实践。"
2025-2026 年,各大模型的编程能力差距越来越小。
GPT-4.5、Claude 3.5、Gemini 2.0...在编程任务上的表现已经趋同。模型本身成了大宗商品。
那什么才是核心竞争力?Harness。
LangChain 的编程 Agent 在 Terminal Bench 2.0 排行榜上发生过一次惊天逆袭:
之前:52.8% 得分,排名 Top 30
之后:66.5% 得分,排名 Top 5
他们做了什么惊天地泣鬼神的事吗?
没有。他们连模型都没换。
只是优化了 Harness:
加了个"完成前检查清单"中间件
启动时自动映射目录结构
实现了"死循环检测"机制
优化了推理资源的分配策略
同样的模型,不同的 Harness,天壤之别的结果。
根据 OpenAI 的官方框架,Harness Engineering 由三大支柱支撑:
核心原则:Agent 应当恰好获得当前任务所需的上下文,不多不少。
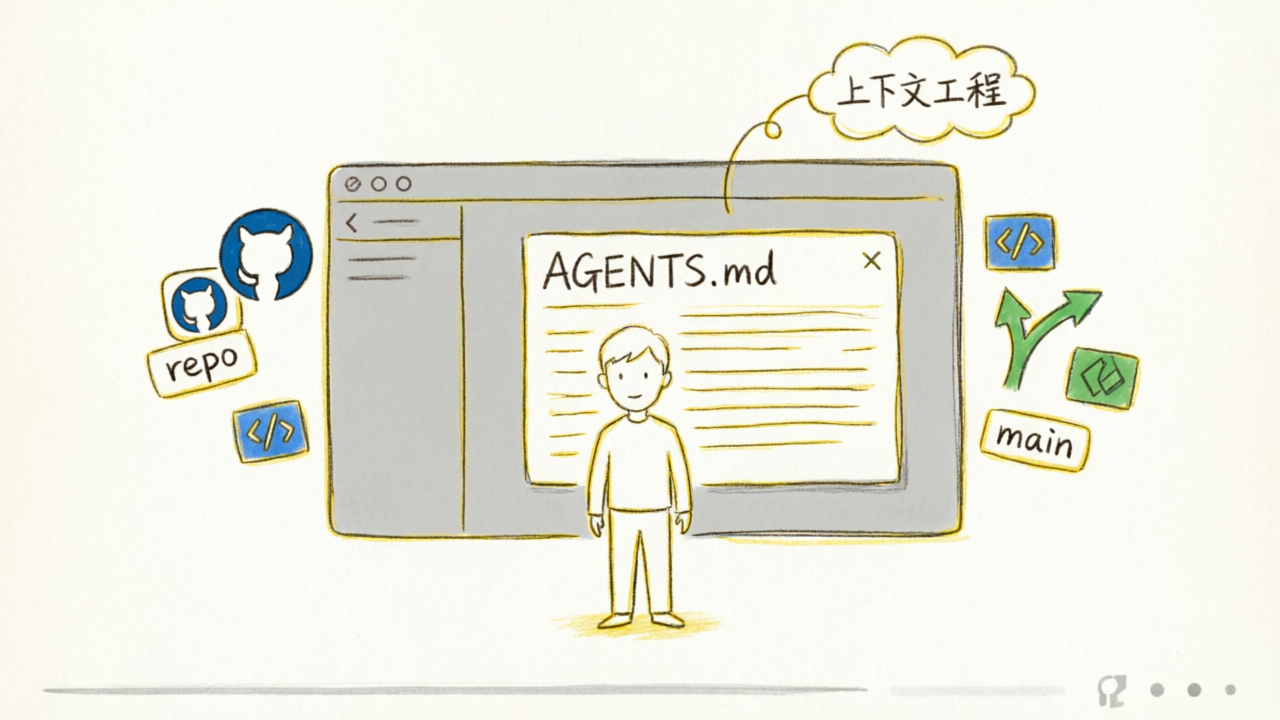
AGENTS.md 或 CLAUDE.md 文件(类似 README,但专门给 AI 看的)
架构规范文档
API 契约
代码风格指南
启动时自动扫描并映射目录结构
实时日志、指标、链路追踪数据
CI/CD 流水线状态和测试结果
其他 Agent 的工作进度
从 Agent 的视角看:任何它在上下文中访问不到的信息,就等于不存在。
写在 Confluence 里的文档?不存在。 Slack 里的讨论?不存在。 某个工程师脑子里的知识?不存在。
代码库必须是唯一的真相源(Single Source of Truth)。
这是 Harness Engineering 最反直觉的部分:
限制越多,效率越高。
Types → Config → Repo → Service → Runtime → UI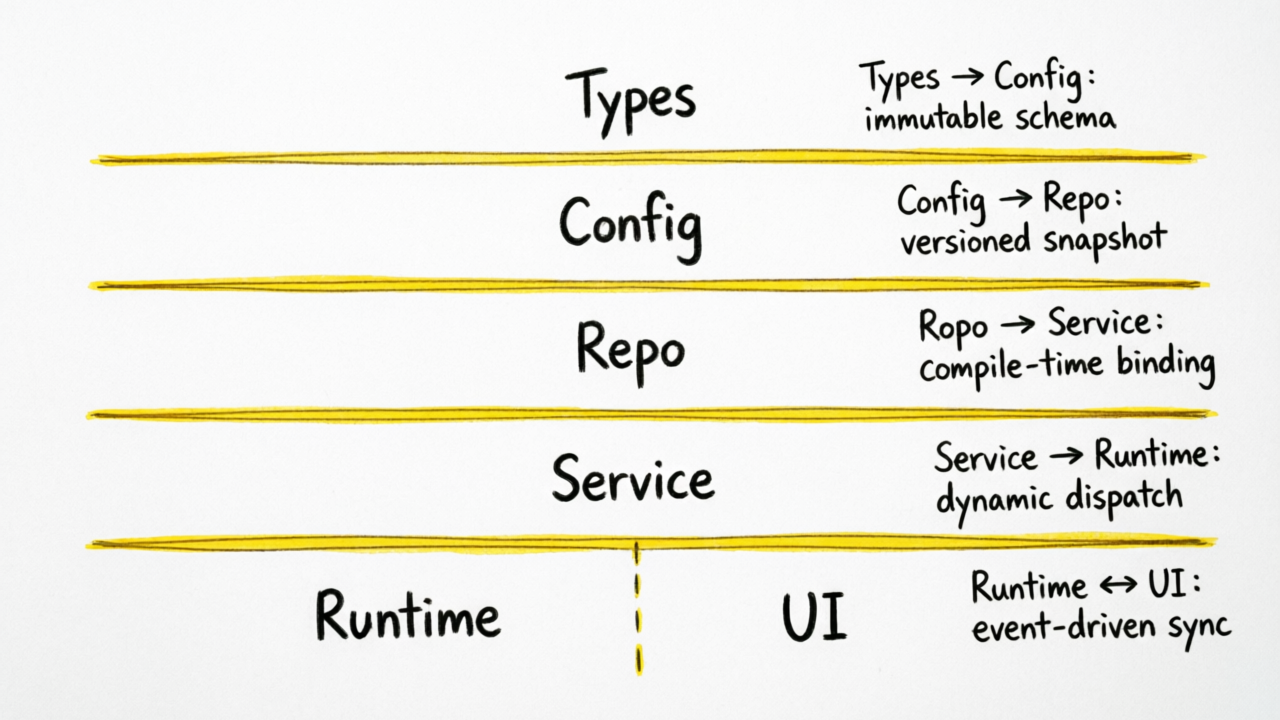
规则:
每一层只能 import 左边的层
绝对不能跨层调用
不能循环依赖
这不是建议,是机械性强制执行。
确定性 Linter:自定义规则,自动检查违规
LLM 审计员:专门有个 Agent 审查其他 Agent 的代码
结构性测试:类似 ArchUnit,但针对 AI 生成的代码
Pre-commit Hook:代码提交前自动检查
想象一下:
场景 A(无约束):Agent 接到任务"实现一个用户服务"
它要思考:放哪个目录?依赖哪些模块?用什么命名规范?
花了 30% 的 token 在探索可能性上
场景 B(强约束):同样的任务
架构明确规定:Service 层,依赖 Repo 和 Config,遵循 XX 命名规范
100% 的 token 都用在解决问题上
约束不是限制创造力,是消除决策疲劳。
这是最容易被忽视,但最重要的部分。
AI 生成的代码库会随着时间积累"混乱":
文档和代码不一致
命名风格越来越不统一
死代码越积越多
架构约束被悄悄打破
这就是熵增。如果不管理,代码库会迅速变成屎山。
定期运行专门的"清理 Agent":
文档一致性 Agent:每天凌晨 2 点扫描,检查文档是否匹配当前代码
约束违规扫描 Agent:找出绕过检查的漏网之鱼
模式执行 Agent:发现并修复不符合设计模式的代码
依赖审计 Agent:追踪并清理循环依赖和多余依赖
这些 Agent 按调度运行:每天、每周,或在特定事件触发时。
就像定期做大扫除,保持代码库宜居。

工程师的日常:
工作重心完全转移。
Stripe 内部的编程 Agent 叫 Minions,每周产生 1000+ 合并的 PR。
工作流程:
开发者在 Slack 发任务
Minion 写代码
Minion 跑 CI
Minion 开 PR
人类审查并合并
第 1 步和第 5 步之间,完全不需要人类参与。
Harness 处理了一切:测试、CI、代码风格、文档更新。
LangChain 把 Harness 设计成可组合的中间件层:
Agent 请求
→ LocalContextMiddleware(映射代码库)
→ LoopDetectionMiddleware(防止死循环)
→ ReasoningSandwichMiddleware(优化计算资源)
→ PreCompletionChecklistMiddleware(强制执行验证)
→ Agent 响应每个中间件层添加特定能力,不修改核心 Agent 逻辑。
模块化的好处:Harness 本身可测试、可演进。
别被大厂案例吓到。Harness Engineering 可以循序渐进。
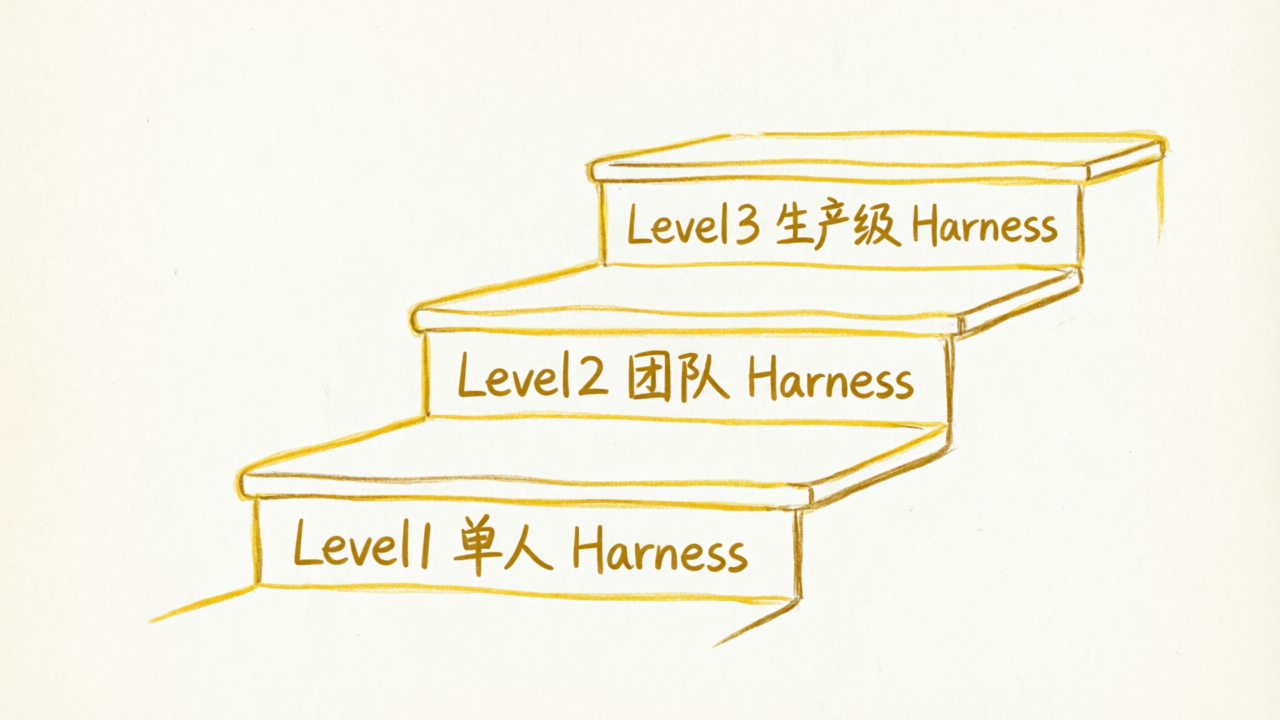
适合:个人开发者,用 Cursor、Claude Code 等工具
最小配置:
项目规则文件(.cursorrules 或 CLAUDE.md)
# 项目约定
- 用 TypeScript
- 遵循 Airbnb 风格指南
- 测试用 Jest
- 目录结构:src/components, src/hooks, src/utilsPre-commit Hook
# 自动格式化和 linting
npm run lint && npm run format测试套件
确保 Agent 能自己跑测试验证
清晰的目录结构
一致的命名规范
效果:防止最常见的 Agent 错误
适合:3-10 人团队
在 Level 1 基础上增加:
AGENTS.md 文件(团队级约定)
# 团队开发规范
- 所有 API 必须带错误处理
- 数据库操作必须用事务
- PR 描述必须包含测试覆盖范围CI 强制执行的架构约束
用 madge 检查循环依赖
用自定义脚本检查分层规则
共享的 Prompt 模板
"实现一个新 API"
"修复一个 bug"
"重构一个模块"
文档即代码
文档用 Markdown 写进代码库
Linter 检查文档是否过期
Agent 生成 PR 的审查清单
代码通过 linting
测试覆盖率不下降
文档已更新
符合架构约束
效果:团队内 Agent 行为一致
适合:工程组织,数十个并发 Agent
在 Level 2 基础上增加:
自定义中间件层
死循环检测
推理资源优化
可观测性集成
Agent 能读取日志和指标
Dashboard 监控 Agent 性能
熵管理 Agent 调度
每天凌晨运行文档检查
每周运行架构审计
Harness 版本化和 A/B 测试
不同项目用不同版本的 Harness
对比效果持续优化
升级策略
Agent 卡住时自动通知人类
定义清晰的 escalation policy
效果:Agent 成为自主贡献者
"如果你把控制流设计得太复杂,下一个模型更新就会让你的系统报废。"
2024 年需要复杂 pipeline 实现的功能,2025 年模型一个 prompt 就能搞定。
建议:Harness 要设计成"可拆卸"的。当模型变聪明后,能轻松移除不必要的控制逻辑。
Harness 需要持续演进:
模型能力提升了 → Harness 要简化
团队规模扩大了 → Harness 要加强
代码库变复杂了 → Harness 要增加约束
建议:每周回顾 Harness 的效果,持续迭代。
很多人把 AGENTS.md 当成普通文档,写完就忘。
大错特错。
AGENTS.md 是 Harness 的核心组件,是 Agent 的"入职培训手册"。
建议:
每次 Agent 犯错,都要更新 AGENTS.md
把 AGENTS.md 当成代码一样维护
用 Linter 检查文档是否过期
约束不足:Agent 漫无目的,产出混乱 约束过度:Agent 束手束脚,无法创新
建议:
从最小约束集开始
根据 Agent 的实际表现逐步调整
定期问:"这个约束还有必要吗?"
传统工程师:
"这个功能我要怎么写?"
Harness 工程师:
"我要设计什么样的环境,才能让 Agent reliably 写出这个功能?"
关注点从实现转移到赋能。
传统工程师:
"这段代码有没有 bug?"
Harness 工程师:
"为什么 Harness 没有防止这个 bug?需要增加什么约束?"
关注点从单点错误转移到系统缺陷。
传统模式:
工程师学习怎么用 AI 工具
Harness 模式:
AI 工具学习怎么在工程师的环境里工作
关注点从学习成本转移到环境设计。
回到最初的问题:
Harness Engineering 会让工程师失业吗?
答案是:不会,但会重新定义"工程师"。
系统设计能力:设计 Harness 比写代码更难
问题拆解能力:把模糊需求变成清晰任务
质量判断能力:评估 Agent 输出的优劣
架构演进能力:随着业务发展调整 Harness
纯体力型的 CRUD 代码
没有创造力的重复劳动
依赖记忆力的 API 调用
更像是:
产品经理(定义要做什么)
架构师(设计怎么做)
教练(训练 Agent 做得更好)
质检员(确保输出质量)
写代码的手速不重要了,设计系统的眼界变得重要。
别等了。今天就可以开始。
在你的项目根目录创建 AGENTS.md:
# 项目概述
这个项目是做什么的
# 技术栈
- 语言:TypeScript
- 框架:React + Node.js
- 数据库:PostgreSQL
# 开发规范
- 用 ESLint + Prettier
- 测试用 Jest
- 所有函数必须有 JSDoc
# 架构约束
- 前端:src/components, src/hooks, src/utils
- 后端:src/controllers, src/services, src/repositories
- 禁止跨层 import
# 常用命令
- npm run test:运行测试
- npm run lint:代码检查
- npm run build:构建设置 Pre-commit Hook:
#!/bin/bash
npm run lint
npm run test每次 Agent 犯错,就更新 AGENTS.md。
一个月后,你会拥有一个越来越聪明的 Harness。
Harness Engineering 不是银弹。
但它代表了一个范式转移:
从"让人适应 AI"到"让 AI 适应人"。
从"怎么用好工具"到"怎么设计环境"。
从"写代码"到"设计让代码能可靠生成的系统"。
2026 年了,别再只关注哪个模型更强。
真正拉开差距的,是谁的 Harness 更聪明。
参考资料:
OpenAI: Harness engineering: leveraging Codex in an agent-first world
Martin Fowler: Harness Engineering
The Emerging "Harness Engineering" Playbook - Artificial Ignorance
Harness Engineering: The Complete Guide - NxCode
互动话题:
你开始尝试 Harness Engineering 了吗? 在评论区分享你的实践经验或困惑!
如果觉得有用,欢迎点赞、在看、转发三连!
