在 AI 大模型横行的今天,Transformer 绝对是绕不开的核心技术。从 ChatGPT 到各种 AI 助手,从文本生成到图像识别,Transformer 无处不在。但很多人一听到 Transformer 就被吓退了:什么 Self-Attention、Multi-Head、Position Encoding……听起来就头大。别慌!今天这篇文章,我就用最通俗的语言,带你彻底搞懂 Transformer 的底层逻辑。看完之后,你会发现:原来 Transformer 也没那么神秘!
在 Transformer 出现之前,处理序列数据(比如一句话、一篇文章)的主流技术是 RNN(循环神经网络) 和 LSTM(长短期记忆网络)。
想象一下,RNN 的工作方式就像你读一句话:一个字一个字地读,读完第一个字,再读第二个字,依次类推……
这种方式有个致命问题:太慢了!
而且,当句子很长时,RNN 很容易"读了后面忘前面"。比如:
"我出生在法国,从小在中国长大,会说流利的中文和。"
要填这个空,你需要记得前面的"法国"和"中国",但 RNN 读到后面时,前面的信息已经忘得差不多了。
2017 年,Google 团队发表了一篇论文:《Attention Is All You Need》(你只需要注意力机制)。
这篇论文的名字就很"嚣张":其他的都不要了,我只要 Attention!
论文提出了一个全新的架构——Transformer,结果让人大跌眼镜:
抛弃了 RNN 和 CNN
完全基于 Attention 机制
训练速度提升了 3-10 倍
效果还更好了!
从此,Transformer 开启了 NLP(自然语言处理)的新纪元,也成为了后来所有大语言模型(LLM)的基石。
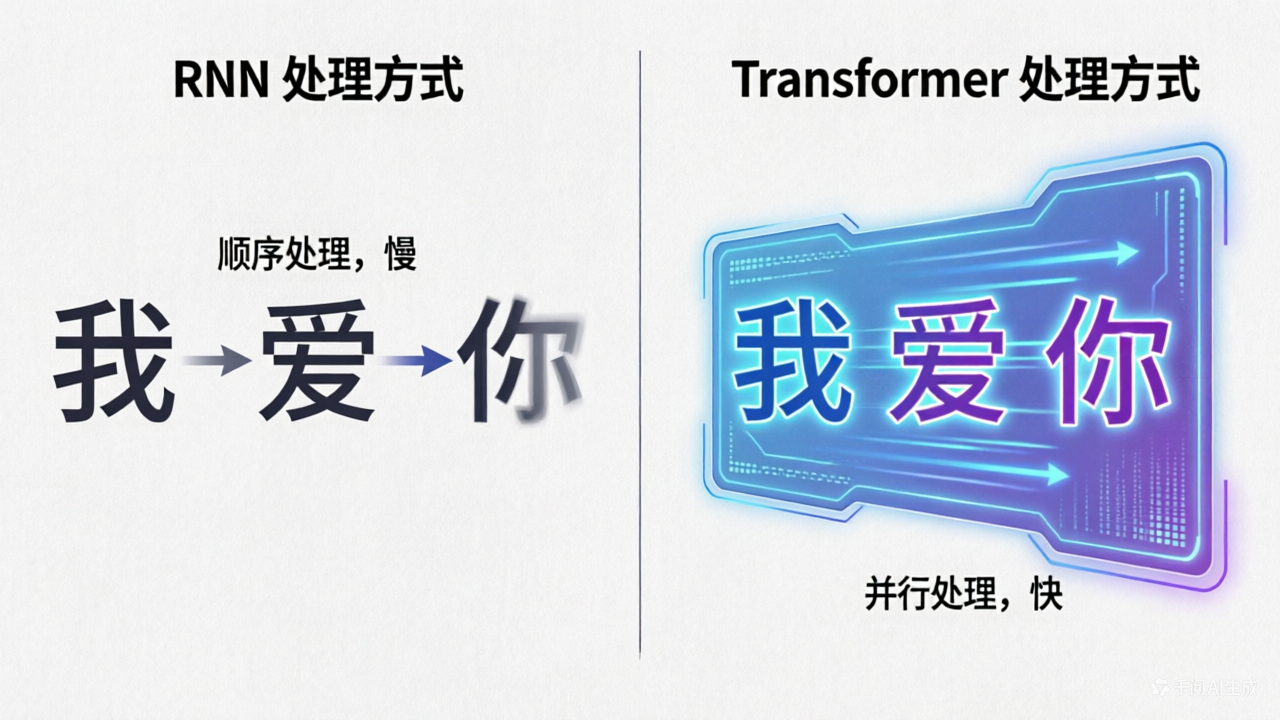
Transformer 最大的创新是什么?并行计算!
还是刚才的例子,RNN 是一个字一个字读,而 Transformer 是一眼扫完整句话,同时处理所有字。
这就像:
RNN:像老式收音机,一首歌听完才能听下一首
Transformer:像 Spotify 播放列表,所有歌一次性加载
好处是什么?快!非常快!
Transformer 的核心是 Self-Attention(自注意力机制)。
听起来很玄乎?其实很简单。
假设有一句话:
"The animal didn't cross the street because it was too tired."
这里的 "it" 指的是什么?是 "animal" 还是 "street"?
人类很容易理解:动物累了,所以不过马路。但机器很难理解这种指代关系。
Self-Attention 的作用就是:让句子中的每个词都和其他词"建立联系",找出谁和谁关系更密切。
具体来说:
"it" 会和 "animal" 建立强连接(因为 it 指的是 animal)
"it" 会和 "tired" 建立连接(因为 tired 描述的是 it 的状态)
"it" 会和 "street" 建立弱连接(关系不大)

这样,模型就能理解:"哦,原来是动物累了,不是街道累了。"
Transformer 的整体架构看起来复杂,其实可以拆解成几个简单的模块。
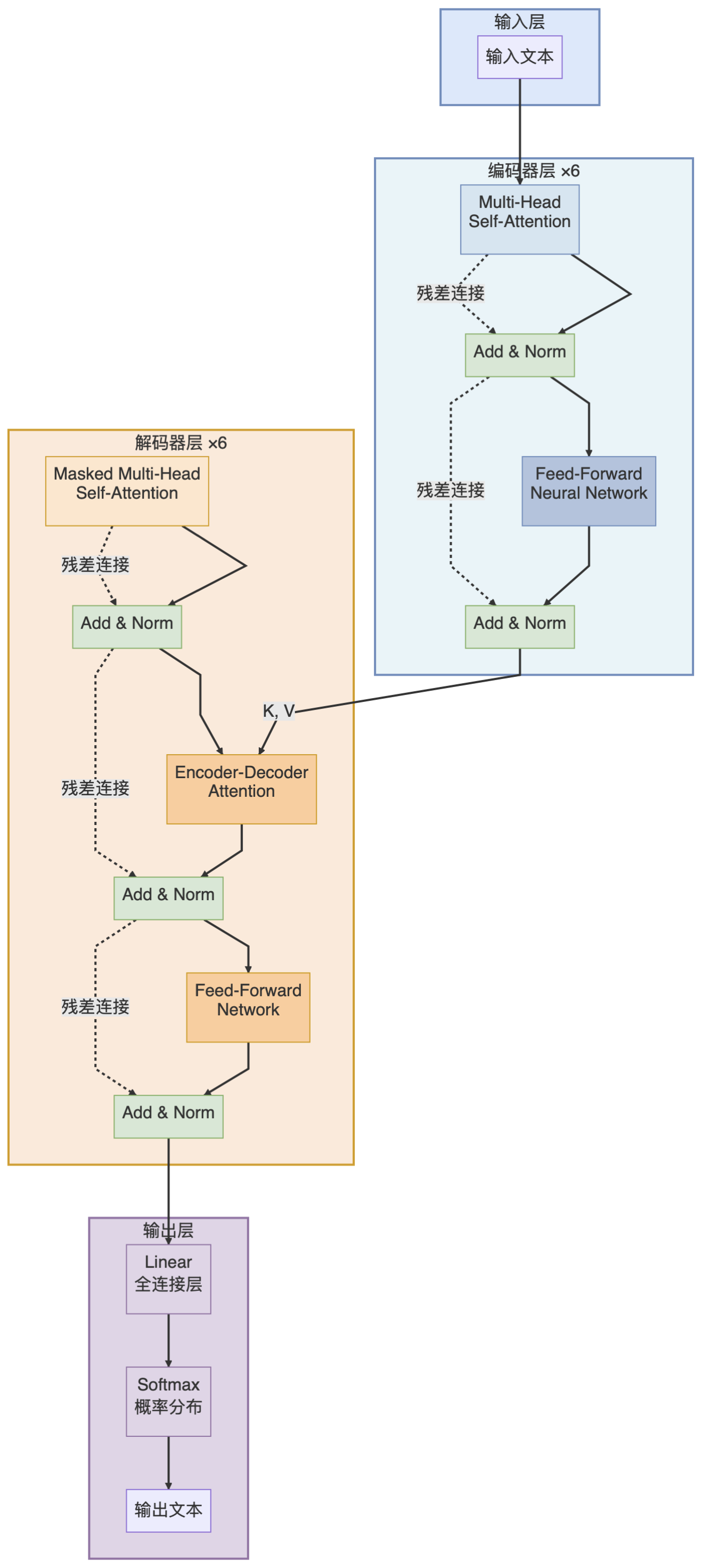
Transformer 采用了 Encoder-Decoder(编码器 - 解码器) 架构:
Encoder(编码器):负责"理解"输入,把输入信息编码成计算机能理解的向量
Decoder(解码器):负责"生成"输出,根据编码信息生成目标内容
计算机不认识文字,所以第一步是把文字转成数字。
这个过程包括三个关键步骤:
把每个词映射成一个固定长度的向量。比如:
"猫" → [0.2, -0.5, 0.8, ...]
"狗" → [0.3, -0.4, 0.7, ...]
Embedding 的本质是:语义相似的词,向量也相似。
这是 Transformer 的一个巧妙设计。
因为 Transformer 是并行处理所有词的,它不知道词的顺序。但顺序很重要啊!
比较这两句话:
"猫追狗"
"狗追猫"
词都一样,但意思完全相反!
所以,Transformer 给每个位置都添加了一个位置编码,让模型知道每个词在句子中的位置。
位置编码的设计很巧妙,用的是正弦和余弦函数,这样模型能轻松学习到相对位置关系。
把 Embedding 和 Position Encoding 相加,得到最终的输入向量。
最终输入 = 词嵌入 + 位置编码Encoder 是 Transformer 的核心,由 6 个相同的层 堆叠而成。后来的模型使用了更多层,比如 BERT-Base 用 12 层,BERT-Large 用 24 层。
每一层包含两个子层:
这是 Transformer 的"灵魂"所在。
为什么要"多头"?
想象你在读一句话,可以从不同角度理解:
语法角度:主谓宾结构
语义角度:谁做了什么
情感角度:是褒义还是贬义
Multi-Head 就是让模型从多个角度同时理解句子。
每个"头"都独立计算 Self-Attention,然后把结果拼接起来。这样,模型就能捕捉到更丰富的信息。
这是一个简单的全连接神经网络,负责对 Attention 的输出做进一步加工。
可以理解为:Attention 负责"理解关系",Feed-Forward 负责"深度思考"。
每个子层后面都有两个"辅助"操作:
Residual Connection(残差连接):把输入直接加到输出上,防止信息丢失
Layer Normalization(层归一化):让数据分布更稳定,训练更快
这两个技术听起来不起眼,但对模型训练至关重要!
Decoder 的结构和 Encoder 类似,也是 6 层堆叠,但多了一个关键组件。
Decoder 的每一层包含三个子层:
为什么要"Masked"(掩码)?
因为 Decoder 在生成时,只能看到已经生成的内容,不能看到未来的内容。
比如翻译时,你只能根据已经翻译的词来预测下一个词,不能偷看答案。
Masked 的作用就是遮住未来的信息,防止作弊。
这一层负责和 Encoder 的输出做交互,可以理解为:Decoder 在生成时,会不断"参考"Encoder 的理解结果。
和 Encoder 一样,负责深度加工。
Decoder 的输出经过一个线性层和 Softmax,变成概率分布,选择概率最大的词作为输出。
Self-Attention 听起来高大上,但计算过程其实很简单。
对于输入序列中的每个词向量,Transformer 会通过三个不同的线性变换矩阵,分别得到三个向量:
Q(Query,查询):我想找什么信息
K(Key,键):我能提供什么信息
V(Value,值):我的实际内容
可以用图书馆检索来理解:
Q:你要找的书的关键词
K:书架上每本书的标签
V:书的实际内容
Self-Attention 的计算分为四步:
用 Q 和 K 做点积(可以理解为计算相似度):
分数 = Q · K^T分数越高,说明两个词的关系越密切。
除以 √d(d 是向量维度),防止数值太大。
用 Softmax 把分数转成概率分布(所有分数加起来等于 1)。
这样,重要的词会获得更高的权重。
用 Softmax 的分数对 V 做加权求和,得到最终的输出。
输出 = Softmax(Q·K^T/√d) · V这就是 Self-Attention 的全部计算过程!
假设有句话:"我喜欢吃苹果"
计算"苹果"的 Self-Attention:
"苹果"的 Q 和其他词的 K 计算相似度:
苹果 - 我:0.8
苹果 - 喜欢:0.9
苹果 - 吃:0.95
苹果 - 苹果:1.0
Softmax 后得到权重:
我:0.15
喜欢:0.20
吃:0.25
苹果:0.40
对 V 加权求和,得到"苹果"的新表示
这样,"苹果"就融合了"我"、"喜欢"、"吃"的信息,表示更丰富了!
这是 Transformer 最大的优势。
RNN 必须按顺序计算,而 Transformer 可以一次性处理整个序列,充分利用 GPU 的并行能力。
训练速度提升 3-10 倍,不是开玩笑的。
Self-Attention 让任意两个词都能直接建立联系,不管它们相距多远。
比如:
"那只黑色的猫追着一只老鼠,因为它饿了。"
Self-Attention 能直接建立"它"和"猫"之间的连接,正确理解是"猫饿了",而不是"老鼠饿了"。
Attention 权重可以可视化,让我们看到模型在关注什么。
比如翻译时,可以看到源句子的哪些词和目标句子的哪些词对应。
这就像打开了黑箱,让我们能理解模型的"思考过程"。
Transformer 最初用于 NLP,后来发现:
图像处理:Vision Transformer (ViT)
语音识别:Audio Transformer
蛋白质结构预测:AlphaFold
甚至音乐生成!
Transformer 成了 AI 界的"万能工具"。
虽然 Transformer 的基本架构没变,但这些年来,研究者们在各个细节上做了大量改进。
原始 Transformer 用正弦/余弦函数做位置编码,后来有了:
相对位置编码:直接编码词与词之间的相对距离
RoPE(旋转位置编码):LLaMA 等模型在用
ALiBi:让模型能处理更长的文本
从原始的 ReLU 变成了:
GELU:BERT、GPT-2 在用
SwiGLU:LLaMA 系列在用,效果更好
原始 Transformer 在每个子层之后做归一化(Post-LN),后来发现:
Pre-LN(在子层之前归一化)训练更稳定
原始的 Self-Attention 计算量很大(O(n²)),后来有了各种优化:
Sparse Attention:只关注部分词
Flash Attention:GPU 优化,速度提升数倍
Multi-Query Attention:减少显存占用
最新的趋势是做减法:
去掉 Decoder,只用 Encoder(如 BERT)
去掉 Encoder,只用 Decoder(如 GPT 系列)
甚至去掉一些层,让模型更轻量
理论讲完了,来看个简单的代码示例(PyTorch):
import torch
import torch.nn as nn
# Self-Attention 的简化实现
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
# 定义 Q、K、V 的线性变换
self.query = nn.Linear(embed_size, embed_size)
self.key = nn.Linear(embed_size, embed_size)
self.value = nn.Linear(embed_size, embed_size)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, x):
N, seq_length, embed_size = x.shape
# 计算 Q、K、V
Q = self.query(x)
K = self.key(x)
V = self.value(x)
# 分割成多个头
Q = Q.view(N, seq_length, self.heads, self.head_dim)
K = K.view(N, seq_length, self.heads, self.head_dim)
V = V.view(N, seq_length, self.heads, self.head_dim)
# 计算注意力分数
energy = torch.einsum('nqhd,nkhd->nhqk', [Q, K])
attention = torch.softmax(energy / (self.head_dim ** 0.5), dim=-1)
# 加权求和
out = torch.einsum('nhql,nlhd->nqhd', [attention, V])
out = out.reshape(N, seq_length, embed_size)
return self.fc_out(out)这就是 Self-Attention 的核心代码,只有几十行!
虽然论文说"Attention Is All You Need",但实际 Transformer 还有很多其他组件:
Feed-Forward Network
Layer Normalization
Residual Connection
少了哪个都不行!
原始 Transformer 用了 6 层,后来的模型用了几十层甚至上百层。
但层数不是越多越好,太多会导致:
训练困难
过拟合
推理速度慢
要根据任务选择合适的层数。
Multi-Head 的数量通常是 8、12、16 等。
但 Head 太多会导致:
每个 Head 的维度变小,表达能力下降
计算量增加
一般选择 8-16 个就够了。
虽然 Transformer 很强,但不是万能的:
对于简单的序列任务,RNN 可能更快
对于某些视觉任务,CNN 仍然有优势
对于实时性要求高的场景,Transformer 可能太重
要根据场景选择合适的架构。
最后,让我们回顾一下 Transformer 的核心要点:
并行计算:同时处理所有输入
Self-Attention:让每个词都和其他词建立联系
Encoder-Decoder 架构:理解 + 生成
Multi-Head Attention:多角度理解
Position Encoding:补充位置信息
Feed-Forward Network:深度加工
残差连接 + LayerNorm:稳定训练
Attention(Q, K, V) = Softmax(Q·K^T/√d) · V快(并行计算)
记得住(长距离依赖)
看得懂(可解释性)
通用(哪里都能用)
如果你已经理解了 Transformer 的基础,接下来可以学习:
BERT:双向 Encoder,用于理解类任务
GPT 系列:单向 Decoder,用于生成类任务
T5:统一的 Encoder-Decoder 框架
位置编码的演进:从绝对位置到相对位置
注意力优化:Flash Attention、Sparse Attention
大模型训练技巧:混合精度、梯度检查点、ZeRO
用 HuggingFace Transformers 库微调模型
从零实现一个简化版 Transformer
参与开源项目,阅读源码
论文:《Attention Is All You Need》
博客:The Illustrated Transformer(可视化讲解)
课程:李宏毅 Transformer 教程(B 站有)
书籍:《深度学习之 Transformer》
Transformer 其实没那么神秘,它的核心思想很简单:
用并行计算提升速度,用 Attention 机制捕捉关系。
理解了这一点,你就理解了 Transformer 的精髓。
当然,要真正掌握 Transformer,还需要大量的实践和探索。但这篇文章已经给了你一张"地图",让你知道该往哪个方向走。
最后,送给大家一句话:
"Attention Is All You Need" —— 但学习 Transformer,还需要一点耐心和坚持。
加油!希望下次见到你时,你已经是一个 Transformer 高手了!
参考资料:
Vaswani et al. "Attention Is All You Need" (2017)
李宏毅 Transformer 教程
HuggingFace Transformers 文档
各类技术博客和教程
希望这篇文章对你有帮助!如果觉得不错,点赞 + 在看 + 分享三连走一波!
关注公众号【码森林】,获取更多 AI 技术干货!

