


使用
join 是 MySQL 用来进行联表操作的,用来匹配两个表的数据,筛选并合并出符合我们要求的结果集。
join 操作有多种方式,取决于最终数据的合并效果。
比如有:
- left join,保留左表所有数据,左边没有数据设置为 null。
- right join,保留右表所有数据,游标没有数据设置为 null。
- inner join,取左右表数据的交集。

原理
MySQL是只支持一种Join算法Nested-Loop Join(嵌套循环连接),并不支持哈希连接和合并连接,不过在mysql中包含了多种变种,能够帮助MySQL提高join执行的效率。
Simple Nested-Loop Join
Simple Nested-Loop Join,简单嵌套循环。这是最简单的方案,性能也一般。对内循环没优化。
假设 A 是驱动表,B 是被驱动表。
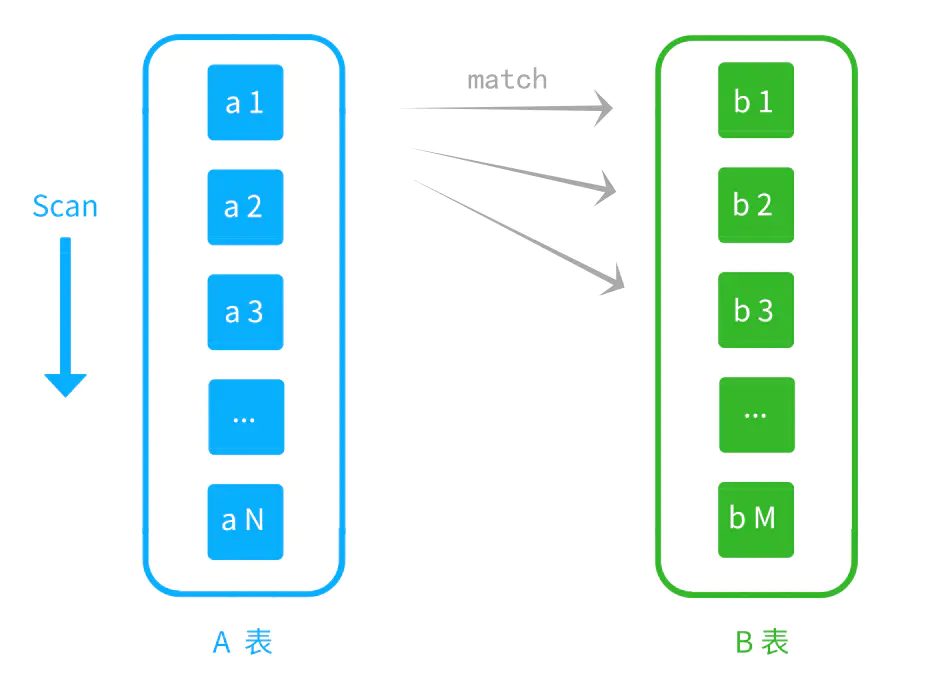
这里会扫描 A 表,将记录一行一行地取出来进行匹配。其实就是用 A 的结果集做为外循环,读取每一行都会触发一个内循环(扫描 B 表)。对 B 表的数据进行比较,加入结果集。
最后根据 join 类型合并驱动表和被驱动表的结果集。看是 left join、right join 还是 inner join,效果在上面有描述过。
伪代码如下:
For each row a in A do
For each row b in B do
If a and b satify the join condition
Then output the tuple
假设 A 表有 N 行,B 表有 M 行。SNL 的开销如下:
- A 表扫描 1 次。
- B 表扫描 N 次。
- 一共有 N 个内循环,每个内循环要 M 次,一共有内循环 N * M 次。有就是比较了 N * M 次。
- 总共读取记录数: N + N * M 。
- 回表读取记录数:0。
Index Nested-Loop Join
Index Nested-Loop Join,索引嵌套循环。
整个算法过程和 SNL 一致,最大的区别在于,用来进行 join 的字段已经在被驱动表中建立了索引。
我们假设 A 是驱动表,B 是被驱动表。
使用聚簇索引:

没有使用聚簇索引,需要增加回表操作:

A 的行数为 N,所以内循环个数没变也是 N,因为还是要对 N 行 A 数据进行比较。但是内循环次数被优化了。
之前的 SNLJ 算法,因为没有索引,每个内循环要扫码一次 B 表。有了索引后,不需要再全表扫描 B 表,而是进行 B 表的索引查询。最终查询和比较的次数大大降低。
伪代码如下:
For each row a in A do
lookup b in B index
if found b == a
Then ouput the tuple
假设 A 表 N 行,B 表 M 行,索引 B+ 树的高度为 IndexHeight。
- A 表扫描 1 次。
- B 表扫描 0 次。因为使用了索引查询。
- 一共有 N 个内循环,每个内循环遍历次数为索引树的高度,为 IndexHeight 次,一共有内循环 N * IndexHeight 次。也就是比较了 N * IndexHeight 次。
- 总共读取的记录数:N + M(match)。M(match) 为索引返回的记录数。
- 回表次数:主键的聚簇索引为,非聚簇索引为 M(match),即每个记录还需要进行一次回表。
这里有个回表问题需要关注一下。
如果要查询的字段为 B 表的主键,使用了主键的聚簇索引,可以直接拿到记录。
如果要查询的字段不是 B 表的主键,使用的不是主键的聚簇索引,而是辅助索引,还需要进行一次回表查主键的聚簇索引。这里的性能会很有很大的下降。
Block Nested-Loop Join
Block Nested-Loop Join,块嵌套循环。
如果 join 的字段有索引,MySQL 会使用 INL 算法。如果没有的话,MySQL 会如何处理?
因为不存在索引了,所以被驱动表需要进行扫描。这里 MySQL 并不会简单粗暴的应用 SNL 算法,而是加入了 buffer 缓冲区,降低了内循环的个数,也就是被驱动表的扫描次数。

这个 buffer 被称为 join buffer,顾名思义,就是用来缓存 join 需要的字段。MySQL 默认 buffer 大小 256K,如果有 n 个 join 操作,会生成 n-1 个 join buffer。
假设这里 A 为驱动表,B 为被驱动表。
在外层循环扫描 A 中的所有记录。扫描的时候,会把需要进行 join 用到的列都缓存到 buffer 中。buffer 中的数据有一个特点,里面的记录不需要一条一条地取出来和 B 表进行比较,而是整个 buffer 和 B 表进行批量比较。
如果我们把 buffer 的空间开得很大,可以容纳下 A 表的所有记录,那么 B 表也只需要访问访问一次。
很显然应用了 buffer ,实际上是加入了一个中间过程,优化内循环发生的次数。
伪代码如下:
For each tuple a In A do
store used column as p from A in join buffer
for each tuple b In B do
If p and b satisfy the join condition
Then ouput the tuple
假设 A 表 N 个记录,B 表 M 个记录。开销如下:
- A 表扫描 1 次。
- B 表扫描的次数和 buffer 的大小有关,
N * (used_column_size)/join_buffer_size + 1。其中used_column_size为 join 字段总大小,join_buffer_size为 buffer 的大小。 - 虽然加了 buffer,但实际上 A 表的每个记录和 B 表的每个记录都进行了比较,有 N * M 次比较。
- 总共读取的记录数: 设置 B 表扫码次数为 H,则这里记录数 = M * H。
- 回表次数:0。不走索引,不存在回表。
小结
以上就是嵌套循环算法的三种实现。
假设有这样的数据:
- 驱动表为 A,记录数 N;被驱动表为 B,记录数 M。
- 如果 join 字段使用索引,B+ 树的深度为 IndexHeight。匹配的记录数为 M(match)。
- 如果 join 字段不使用索引,使用的 buffer 大小为
join_buffer_size,join 字段的总大小为used_column_size。
三种实现的效率比较如下:
| SNLJ | INLJ | BNLJ | |
|---|---|---|---|
| 驱动表扫描次数 | 1 | 1 | 1 |
| 被驱动表扫描次数 | N | 0 | N * (used_column_size) / join_buffer_size + 1 |
| join 比较次数 | N * M | N + M(match) | N * M |
| 回表次数 | 0 | M(match) | 0 |
虽然 BNL 效率比 SNL 快很多,但是这并不是最优的方式。在执行计划 Explain 中如果发现使用了块嵌套循环的实现,要检查一下 sql,考虑对 join 的字段加入索引。
总的来说,应用 join 需要注意:
- 用来进行 join 的字段要加索引,会触发 INLJ 算法,如果是主键的聚簇索引,性能最优。
- 如果无法使用索引,那么注意调整 join buffer 大小,适当调大些。
- 小结果集驱动大结果集。用数据量小的表去驱动数据量大的表,这样可以减少内循环个数,也就是被驱动表的扫描次数。
评论区